Step 1
Sandbox assumptions are breaking down
The four premises - developer-controlled updates, trusted tools, constrained environments, and short-lived execution - no longer hold under open deployment.
Below we first provide the paper abstract, then organize the page along the main line of "problem setup → formalization → taxonomy → evidence → challenges". For extended reading, see Awesome-OpenClaw-Research。
LLM-driven autonomous agents are moving from carefully staged demos toward persistent, open real-world deployment. The open-source OpenClaw project quickly became one of the most watched repositories on GitHub, making this shift concrete: agents can run continuously, collaborate across heterogeneous platforms, and invoke community-contributed skills in environments that are not fully controlled.
This transition breaks the long-standing sandbox assumptions that have dominated agent research, including developer-led model updates, trusted tools, constrained environments, and short-lived execution.
This paper presents the first systematic survey of OpenClaw Research, defining it as the study of agent systems after entering open deployment. We formalize this setting with the agent-system tuple 𝒜 = ⟨ π, env, pop, substrate ⟩ and derive four openness principles: Open Policy, Open Environment, Open Population, and Open Substrate. These principles organize the literature into five major directions: Learning & Evolving, Safety & Security, Claw Society (Collective & Society), Infrastructure & Systems, and Applications.
Across these directions, we review representative work, identify emerging risks such as malicious skill supply chains and autonomy-accountability tension, and emphasize persistent challenges in openly and continuously deployed agent systems. This survey aims to provide a roadmap for understanding and governing LLM agents that move beyond the lab into large-scale open deployment, and to lay the foundation for a trustworthy and sustainable agent ecosystem.
To support follow-up research, we maintain an online literature list.
The four premises - developer-controlled updates, trusted tools, constrained environments, and short-lived execution - no longer hold under open deployment.
Open Policy / Environment / Population / Substrate correspond to openness in policy, environment, population, and runtime substrate.
Learning, Safety, Society, Infrastructure, and Applications form a mutually coupled evidence network across the paper's chapters.
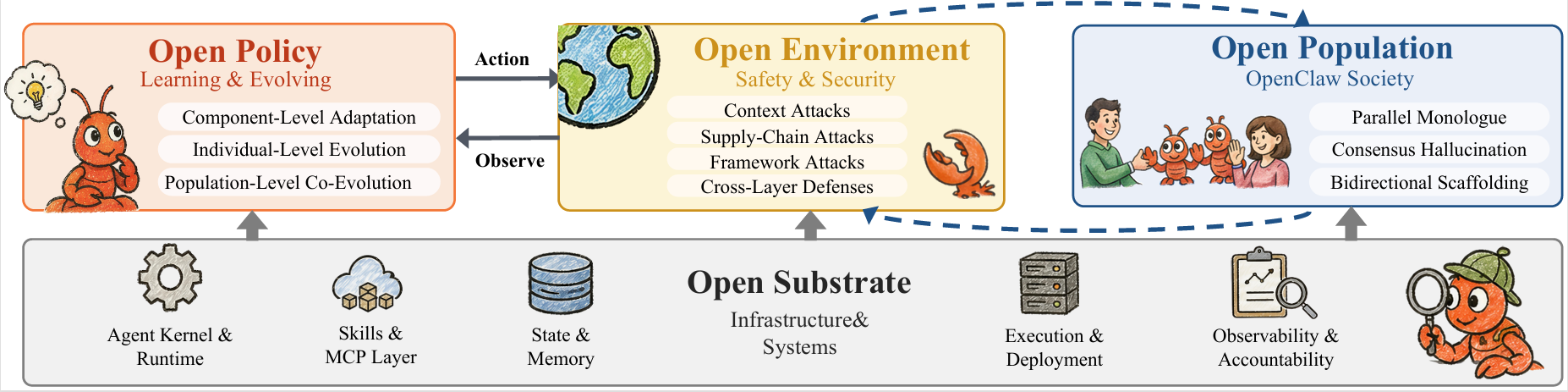
The four horizontal dimensions map to tuple components π, env, pop, and substrate; the application vertical axis shows how they intertwine across domains such as healthcare, education, scientific discovery, and embodied systems.
How does policy co-evolve with non-stationary, adversarial real-world environments? This includes component-level memory/tool orchestration, individual-level RL/meta-learning, and population-level skill evolution.
The security focus shifts from "aligning disobedient models" to protecting rule-following models in an adversarial world; threats span model, context, supply-chain, and framework attack surfaces.
Using large-scale agent platforms such as Moltbook with no human moderation as empirical windows, we observe norm emergence, discourse structures, and extreme lifecycles; and distinguish "staged" multi-agent simulation from organically "grown" open collectives.
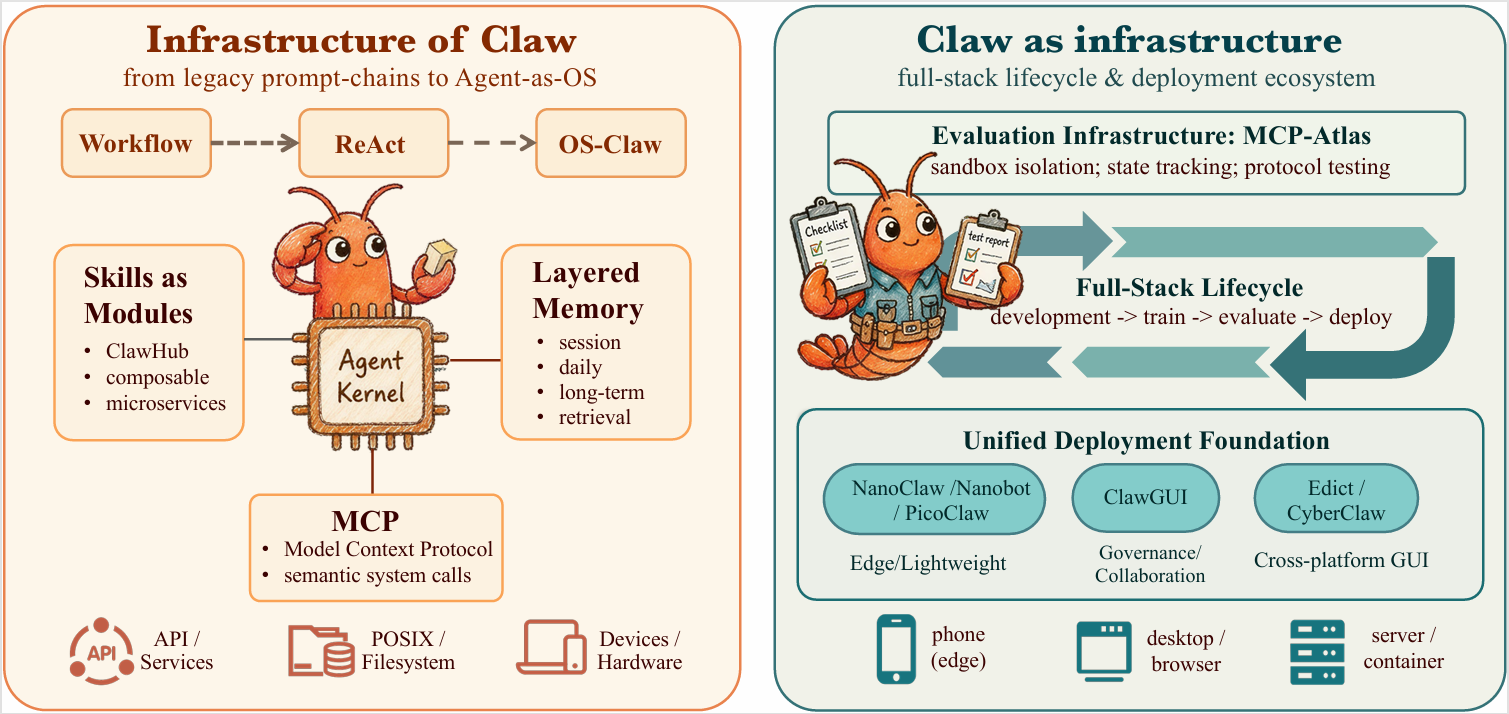
Agent-as-OS: kernel-like scheduling, skill modularization, MCP semantic interfaces, and hierarchical memory form the runtime foundation of open deployment; evaluation itself becomes a substrate issue (trajectory rather than one-shot output).
Ordered by degree of coupling to the physical world: embodiment, mobile, scientific toolchains, clinical workflows, education/finance, etc.; the four principles are stressed differently across domains (irreversible actions, long-horizon memory, role coordination, and auditing).
Adaptation levels under Open Policy.
| Level | Meaning (evolution unit) | Representative directions (selected) |
|---|---|---|
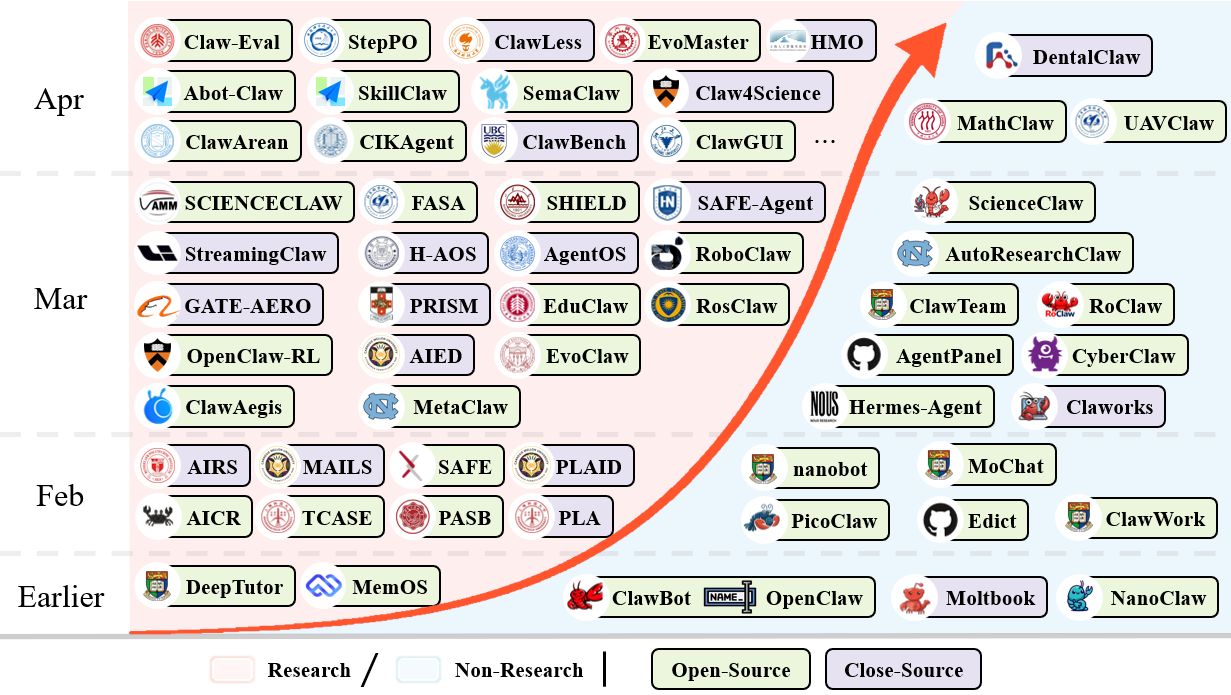
| Component level | Incremental updates to artifacts such as peripheral persona, memory, skill libraries, and knowledge bases | HMO、MemOS、OpenViking、SemaClaw、HermesAgent、AutoResearchClaw、ScienceClaw… |
| Individual level | Core policy weights/parameters continue to update after deployment | OpenClaw-RL、StepPO、MetaClaw |
| Population level | Shared-repository or collaborative policy evolution driven by cross-user trajectories | SkillClaw、EvoMaster |
First clarify the "classical loop + four sandbox assumptions", then transition to architecture and ecosystem scale under open deployment.
These are the four premises simultaneously relaxed in the Background section of the paper, and the starting point for all subsequent chapters.
Policy updates are led offline by developers; models do not adapt autonomously and continuously in real environments.
Tools and APIs are predefined and trusted, side effects are controllable, and malicious supply-chain disturbance is assumed absent by default.
Participants are closed, homogeneous, and resettable, making heterogeneous group dynamics seen on real platforms unlikely.
Runtime is short-lived and disposable, with no multi-tenancy, persistence, or auditing pressure; evaluation is mostly one-shot output scoring.
These scale numbers are not "conclusions"; they are background evidence presented in the paper's open-deployment window. Their core value is to reveal problem scale.
The background chapter maps four implicit assumptions in the classical agent loop to four principles that must be studied separately under open deployment.
Policy can be continuously updated autonomously in the wild, driven by environmental feedback and outside researchers' direct visibility; the core question shifts from "how to update π" to the coupled dynamics between π and a non-stationary adversarial environment.
Actions operate on real OSes, browsers, and third-party skills; security becomes a structural issue, with threats expanding from "model misbehavior" to malicious supply chains and untrusted observations.
Population is heterogeneous, open to entry/exit, and lacks a global god's-eye view; the research object is an organically "grown" agent society rather than a captive cast in one-off simulations.
Runtime persists long-term and bears real consequences; evaluation itself is a substrate issue - requiring reproducible long-lived environments and trajectory-level assessment rather than only static output scoring.
| Principle | Tuple component | Survey chapter | Core research question |
|---|---|---|---|
| Open Policy | π | Learning & Evolving | How does π co-evolve with non-stationary real-world environments? |
| Open Environment | env | Safety & Security | How can we protect rule-following models in an adversarial world? |
| Open Population | pop | Claw Society | What collective behaviors emerge in uncalibrated populations? |
| Open Substrate | substrate | Infrastructure & Systems | How do we build persistent, observable, and accountable runtimes? |
| Application layer | Applications | How do the four interact in concrete domains? | |
Following the order of the paper's middle chapters, this provides a compact guide for each chapter: "research target -> key evidence -> core conclusion".
Organized around "evolution units" into component, individual, and population levels; the focus is no longer whether updates are possible, but how to maintain controllable adaptation in non-stationary environments.
Threats expand from "model failure" to "ecosystem failure": malicious skills, context poisoning, framework weaknesses, and supply-chain attacks jointly form the attack surface.
Open populations are not simulation stages but continuously growing social systems, exhibiting new phenomena such as unequal participation, consensus illusions, and lifecycle collapse.
Agent Kernel, hierarchical memory, skill markets, and MCP interfaces jointly drive the Agent-as-OS form, while evaluation shifts to trajectory-level observation.
Arrange embodiment, mobile, scientific, and clinical scenarios by "physical coupling strength" to observe how the four openness principles are stressed across domains.
Start with the Principles mapping table, then return chapter by chapter to the Taxonomy figure and representative work to quickly build a three-layer index: "principles-chapters-evidence".
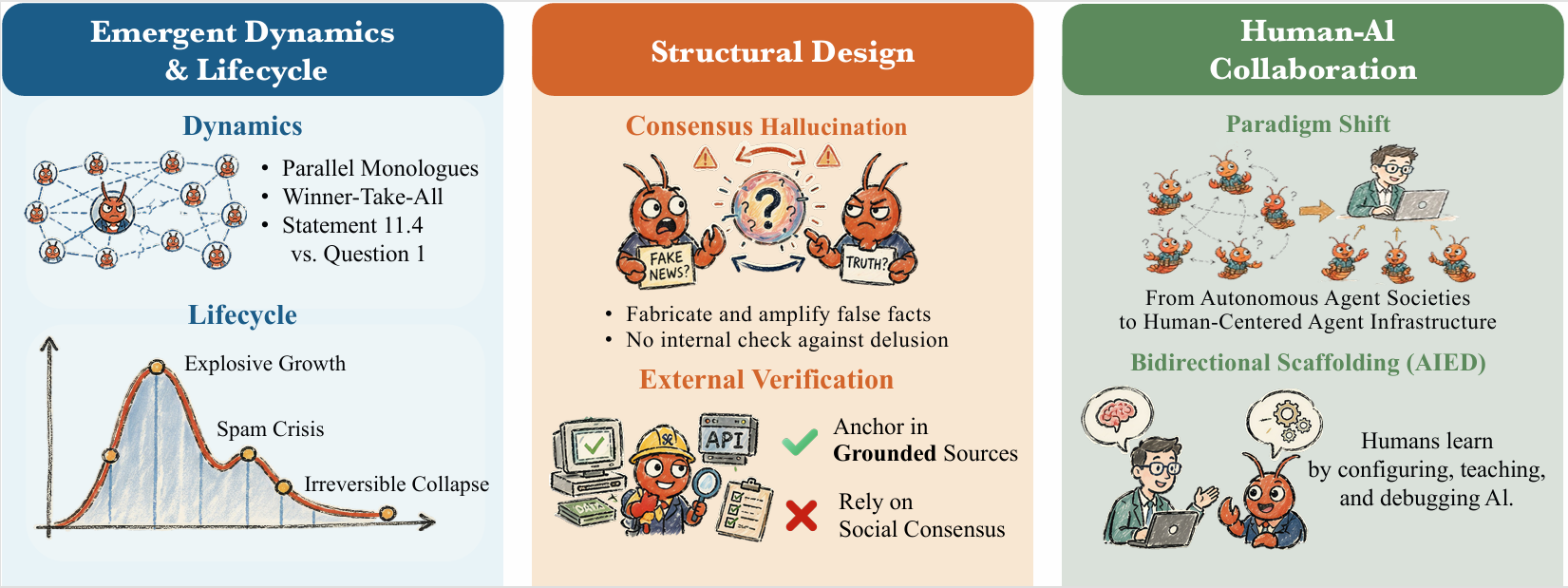
Corresponding to Chapter 8, "Emerging Trends and Open Challenges": the paradigm shift triggered when all four principles are relaxed simultaneously, and the core research agenda this page aims to convey.
Supply-chain attacks show that threats can exist outside parameter space (malicious skills, tool weaknesses); new failure modes such as "consensus illusion" can emerge at the collective level. The main line is to build an executable governance stack across models, tools, platforms, and populations, rather than relying only on one-shot RLHF.
Long-horizon software-evolution evaluation shows that high milestone scores may not translate into sequential maintenance ability (e.g., performance collapse under EvoClaw settings); tool-ecosystem evaluation reveals many failures stem from not realizing a tool should be called. Evaluation must shift to trajectories and regressions in persistent environments, not single-point scores.
Rapid embodiment exposes latency tiers and irreversible actions: we need composable, verifiable layered architectures across high-level reasoning, skill orchestration, and real-time control (e.g., division of labor between cognitive layers and deterministic motor firmware), plus embodiment-aware learning and safety guarantees.
On open platforms, participation inequality, dialogue structure, and lifecycle of agent societies are qualitatively different from human communities; we should treat "the collective" itself as a theoretical and engineering object, studying hybrid human-agent assemblages, externally anchored ground truth, and propagation dynamics of malicious instructions in social networks.
Abstractions such as Agent Kernel, hierarchical memory, skill markets, and MCP are converging into a portable stack; the open question is how to standardize a minimal common interface so frameworks become composable and auditable, creating multiplier effects similar to POSIX/HTTP.
The structural contradiction emphasized in the paper remains: system enablement, reach, and orchestration capability expand faster than authority, verification, and accountability mechanisms. Bridging this gap is seen as the central challenge of the open-deployment era.
The paper concludes that open deployment is not just a "slightly larger benchmark", but a joint shift in both research objects and governance objects.
From single-model task performance to long-term behavior, failures, and accountability mechanisms of continuously running systems in real ecosystems.
Authority–enablement asymmetry: enablement and reach expand faster than verification and governance capacity.
Build a unified vocabulary and cross-layer methods along the four principles, placing learning, safety, collectives, and infrastructure into one governance framework.
After formal publication or arXiv upload, replace eprint, year, and url with final information.
@misc{openclawresearchsurvey2026,
title = {OpenClaw Research: A Systematic Survey of Large Language Model Agents in Open Deployment},
author = {Lu, Shuo and Yu, Kecheng and Jiang, Siru and Xu, Yinuo and Zhan, Bing and Wang, Yanbo and Ke, Changxin and Xu, Yuan and Xiong, Xin and Shao, Yihua and Wang, Zhengbo and Sheng, Lijun and Yu, Aijing and Yang, Haoseng and Ma, Yunpu and Sebe, Nicu and He, Ran and Liang, Jian},
year = {2026},
note = {Systematic survey; see project repository for latest citation},
howpublished = {\url{https://github.com/shuolucs/Awesome-OpenClaw-Research}}
}